
In this study, researchers build evaluation tasks from naturally-occurring textual resources.
Author: Mingda Chen. Table of Links Abstract Acknowledgements 1 INTRODUCTION 1.1 Overview 1.2 Contributions 2 BACKGROUND 2.1 Self-Supervised Language Pretraining 2.2 Naturally-Occurring Data Structures 2.3 Sentence Variational Autoencoder 2.4 Summary 3 IMPROVING SELF-SUPERVISION FOR LANGUAGE PRETRAINING 3.1 Improving Language Representation Learning via Sentence Ordering Prediction 3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training 3.
requires drawing information from utterances across a wide range of the input and integrating the information to form concise plot descriptions. Moreover, since actual TV episodes ground their scripts with audio-visual accompaniment, many details may be omitted from the transcript itself.
from the TV show “The Big Bang Theory”. The transcript documents a dialogue involving four characters about playing a board game, and the recap summarizes the dialogue into sentences. Dataset Construction. We use two sources to construct has longer summaries, its fraction of overlapping four-gram is comparable to XSum which is known for abstractiveness, suggesting that
has longer source inputs. Compared to other dialogue summarization datasets, is large enough to train and evaluate neural methods. The Spotify Podcast Dataset and StreamHover are similar to , and the average number of speakers per instance is only a quarter of that in . We note that since the meaning of sentences in transcripts is highly contextdependent, extractive summarization approaches are not expected to be useful for this dataset. We report the results from nearest neighbor-based extractive summarizers mostly for characterizing the dataset. Neural Models. We use transformer based sequence-to-sequence architectures . Because transcripts are quite long, we limit the number of encoder hidden vectors that are used in the decoder’s attention mechanism.
. Anonymized question answering datasets have also been created out of similar concerns to those just described . Results for Anonymized . Several aspects of An instance in , we filter out instances based on two criteria. First, the overlap ratio of TV show characters appearing in the recap and its transcript should be higher than 85%. We use this criterion to ensure that the alignments between recaps and transcripts are correct. Second, the number of transcript lines that have speaker information should be larger than 100. We use this criterion to eliminate transcripts that are essentially subtitles, i.e., utterances without speaker information.
to other abstractive dialogue summarization datasets in Table 6.15. has far more instances. Unlike most of the other datasets, has larger numbers of speakers per instance. The TV series genre focuses on narrative, which is typically entity-centric and can include multiple parallel subplots in a single episode. Compared to other dialogue summarization datasets,
contains many episodes of a single show . This episodic structure could be used to model character arcs, the evolution of character personality traits and character relationships over episodes, among others. Unlike most of the other datasets, , which has human-written transcripts. Since MediaSum is constructed from news transcripts, it is the most similar dataset in Table 6.15 to
. Since the transcripts focus on dialogue among characters, along with limited descriptions of scenes and actions, it leads to the challenge that plot information is not stated explicitly but rather only implied in the dialogue. For example, the transcript in Fig. 6.2 does not explicitly describe what Sheldon and Leonard are playing.
Philippines Latest News, Philippines Headlines
Similar News:You can also read news stories similar to this one that we have collected from other news sources.
 Tailoring Textual Resources for Evaluation Tasks: Long-Form Data-to-Text GenerationIn this study, researchers build evaluation tasks from naturally-occurring textual resources.
Tailoring Textual Resources for Evaluation Tasks: Long-Form Data-to-Text GenerationIn this study, researchers build evaluation tasks from naturally-occurring textual resources.
Read more »
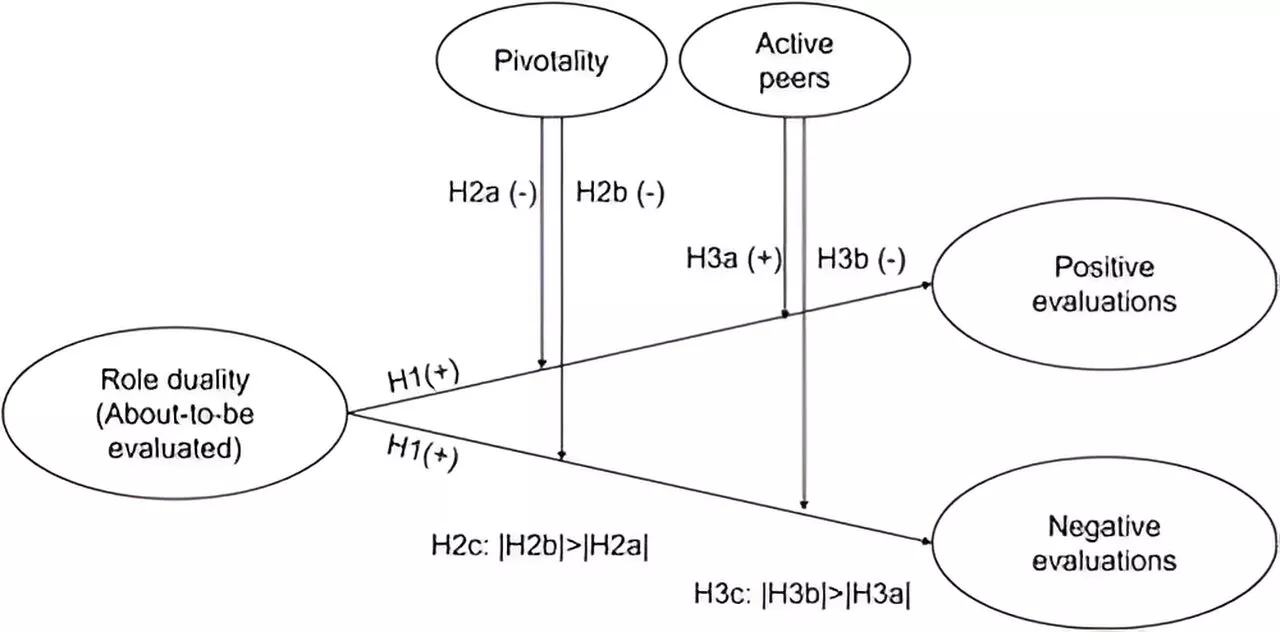 Study finds individuals less likely to evaluate peers negatively if facing evaluation themselvesNew research from ESMT Berlin finds that individuals strategically select the colleagues they evaluate, and the evaluation they give, based on how they want to be perceived. The research was published in the journal Organization Science.
Study finds individuals less likely to evaluate peers negatively if facing evaluation themselvesNew research from ESMT Berlin finds that individuals strategically select the colleagues they evaluate, and the evaluation they give, based on how they want to be perceived. The research was published in the journal Organization Science.
Read more »
 25 Best Petite Jeans for Women 2024 That Don’t Need TailoringOne Vogue editor searches for the best petite jeans for women, from high-rise styles to straight-leg fits. Shop her go-to finds that don’t need alterations.
25 Best Petite Jeans for Women 2024 That Don’t Need TailoringOne Vogue editor searches for the best petite jeans for women, from high-rise styles to straight-leg fits. Shop her go-to finds that don’t need alterations.
Read more »
 Independent evaluation of mental competency granted for accused killer of El Cajon dentistRyan Hill is stoked to be in San Diego! He’s coming to the area from Sacramento. So, he only had to shuffle his area codes around a little bit, trading the 916 for the 619.
Independent evaluation of mental competency granted for accused killer of El Cajon dentistRyan Hill is stoked to be in San Diego! He’s coming to the area from Sacramento. So, he only had to shuffle his area codes around a little bit, trading the 916 for the 619.
Read more »
 End Of Season Evaluation: Jazz SG Jordan ClarksonThe Utah Jazz have a decision to make with their most tenured player
End Of Season Evaluation: Jazz SG Jordan ClarksonThe Utah Jazz have a decision to make with their most tenured player
Read more »
 Evaluation of Project Roomkey finds program had lasting impact on homelessnessAn independent evaluation of Project Roomkey found that 22% of participants moved into permanent housing.
Evaluation of Project Roomkey finds program had lasting impact on homelessnessAn independent evaluation of Project Roomkey found that 22% of participants moved into permanent housing.
Read more »